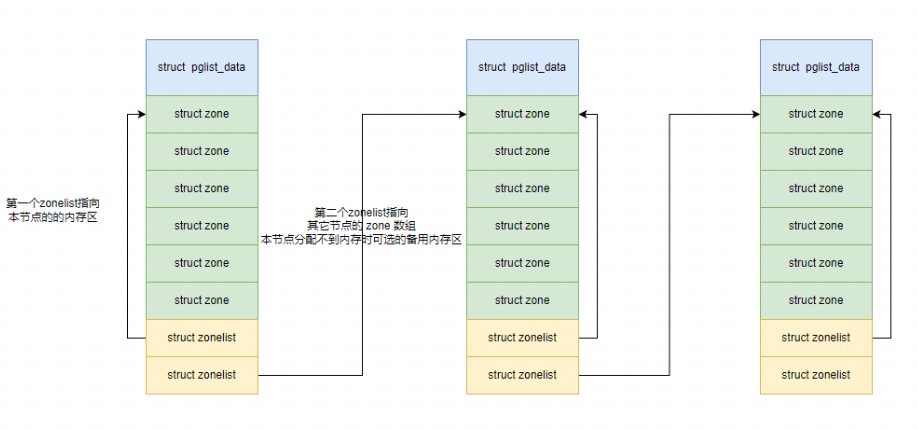
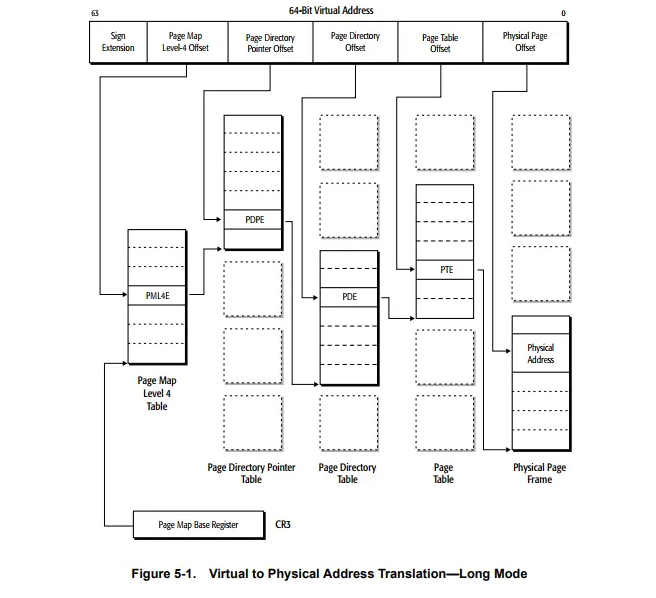
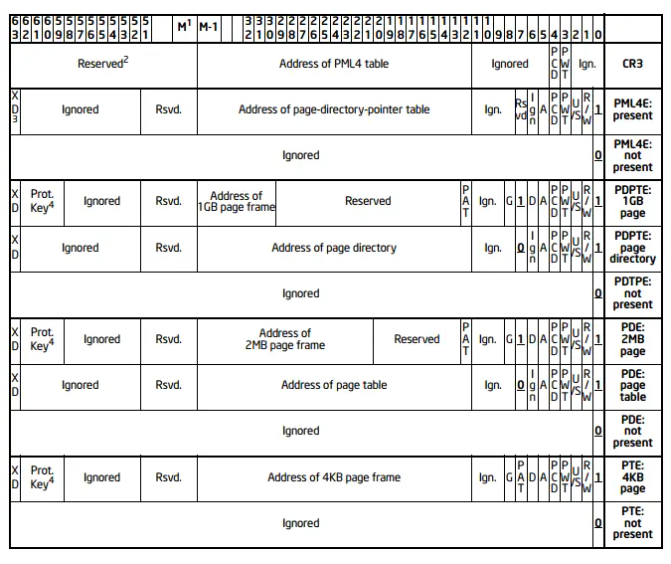
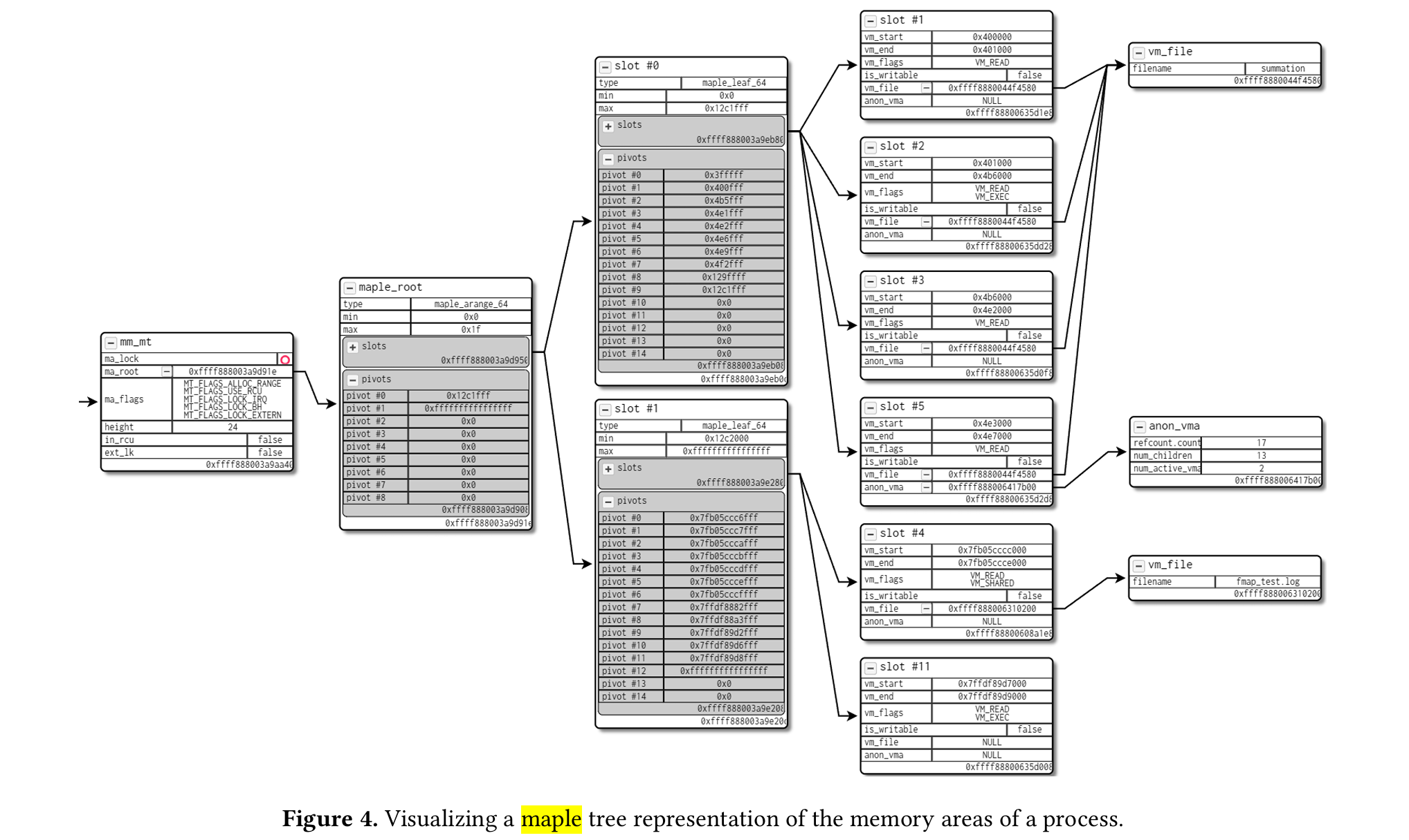
typedefstructpglist_data { /* * node_zones contains just the zones for THIS node. Not all of the * zones may be populated, but it is the full list. It is referenced by * this node's node_zonelists as well as other node's node_zonelists. */ structzonenode_zones[MAX_NR_ZONES];//一个节点包含多个内存区(zone)例如: ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM(在x86 32bit).每个 struct zone 管理该区域的页框分配、回收、空闲页、伙伴系统等。
/* * node_zonelists contains references to all zones in all nodes. * Generally the first zones will be references to this node's * node_zones. */ structzonelistnode_zonelists[MAX_ZONELISTS];
int nr_zones; /* number of populated zones in this node *///当前节点上实际被初始化的 zone 数量。 #ifdef CONFIG_FLATMEM /* means !SPARSEMEM */ structpage *node_mem_map;//这是节点的 struct page 数组(即 “mem_map”),每个物理页框对应一个 struct page。 #ifdef CONFIG_PAGE_EXTENSION structpage_ext *node_page_ext; #endif #endif ...... } pg_data_t;
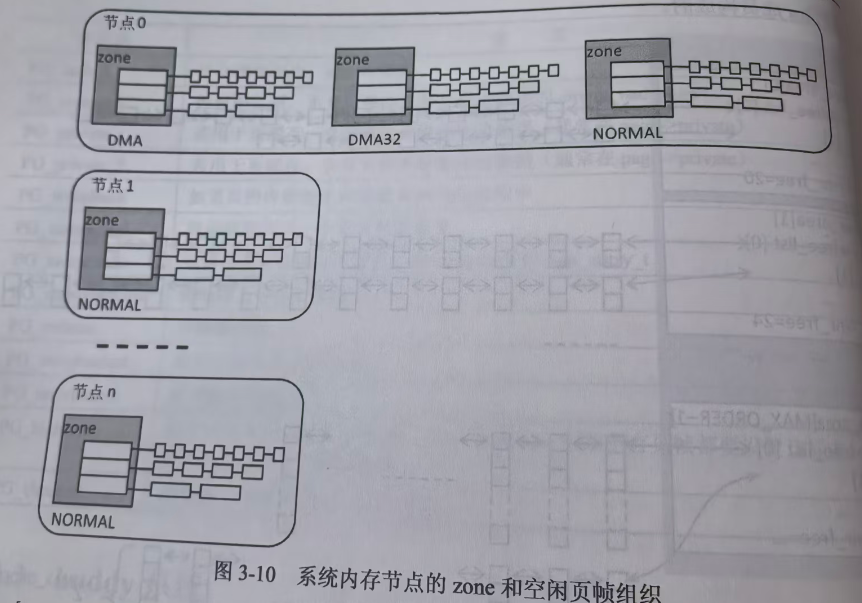
enumzone_type { /* * ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able * to DMA to all of the addressable memory (ZONE_NORMAL). * On architectures where this area covers the whole 32 bit address * space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller * DMA addressing constraints. This distinction is important as a 32bit * DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit * platforms may need both zones as they support peripherals with * different DMA addressing limitations. */ #ifdef CONFIG_ZONE_DMA ZONE_DMA, //低端 DMA 可达内存区(通常为 <16MB 或 <32MB) #endif #ifdef CONFIG_ZONE_DMA32 ZONE_DMA32, //低端 DMA 可达内存区(通常为 <16MB 或 <32MB) #endif /* * Normal addressable memory is in ZONE_NORMAL. DMA operations can be * performed on pages in ZONE_NORMAL if the DMA devices support * transfers to all addressable memory. */ ZONE_NORMAL,//普通的、内核直接线性映射的物理内存区。 #ifdef CONFIG_HIGHMEM /* * A memory area that is only addressable by the kernel through * mapping portions into its own address space. This is for example * used by i386 to allow the kernel to address the memory beyond * 900MB. The kernel will set up special mappings (page * table entries on i386) for each page that the kernel needs to * access. */ ZONE_HIGHMEM, //高端内存区:CPU 不能直接线性映射访问的物理内存。 #endif /* * ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains * movable pages with few exceptional cases described below. Main use * cases for ZONE_MOVABLE are to make memory offlining/unplug more * likely to succeed, and to locally limit unmovable allocations - e.g., * to increase the number of THP/huge pages. Notable special cases are: * * 1. Pinned pages: (long-term) pinning of movable pages might * essentially turn such pages unmovable. Therefore, we do not allow * pinning long-term pages in ZONE_MOVABLE. When pages are pinned and * faulted, they come from the right zone right away. However, it is * still possible that address space already has pages in * ZONE_MOVABLE at the time when pages are pinned (i.e. user has * touches that memory before pinning). In such case we migrate them * to a different zone. When migration fails - pinning fails. * 2. memblock allocations: kernelcore/movablecore setups might create * situations where ZONE_MOVABLE contains unmovable allocations * after boot. Memory offlining and allocations fail early. * 3. Memory holes: kernelcore/movablecore setups might create very rare * situations where ZONE_MOVABLE contains memory holes after boot, * for example, if we have sections that are only partially * populated. Memory offlining and allocations fail early. * 4. PG_hwpoison pages: while poisoned pages can be skipped during * memory offlining, such pages cannot be allocated. * 5. Unmovable PG_offline pages: in paravirtualized environments, * hotplugged memory blocks might only partially be managed by the * buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The * parts not manged by the buddy are unmovable PG_offline pages. In * some cases (virtio-mem), such pages can be skipped during * memory offlining, however, cannot be moved/allocated. These * techniques might use alloc_contig_range() to hide previously * exposed pages from the buddy again (e.g., to implement some sort * of memory unplug in virtio-mem). * 6. ZERO_PAGE(0), kernelcore/movablecore setups might create * situations where ZERO_PAGE(0) which is allocated differently * on different platforms may end up in a movable zone. ZERO_PAGE(0) * cannot be migrated. * 7. Memory-hotplug: when using memmap_on_memory and onlining the * memory to the MOVABLE zone, the vmemmap pages are also placed in * such zone. Such pages cannot be really moved around as they are * self-stored in the range, but they are treated as movable when * the range they describe is about to be offlined. * * In general, no unmovable allocations that degrade memory offlining * should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range()) * have to expect that migrating pages in ZONE_MOVABLE can fail (even * if has_unmovable_pages() states that there are no unmovable pages, * there can be false negatives). */ ZONE_MOVABLE, //可迁移内存区,主要用于内存热插拔和大页管理。 #ifdef CONFIG_ZONE_DEVICE ZONE_DEVICE, //设备专用内存区(非标准 DRAM 页),如持久内存(NVDIMM)、GPU BAR、CXL Memory。 #endif __MAX_NR_ZONES
/* zone watermarks, access with *_wmark_pages(zone) macros */ unsignedlong _watermark[NR_WMARK]; //本内存区域的三个水线,高中低 unsignedlong watermark_boost;
unsignedlong nr_reserved_highatomic;
/* * We don't know if the memory that we're going to allocate will be * freeable or/and it will be released eventually, so to avoid totally * wasting several GB of ram we must reserve some of the lower zone * memory (otherwise we risk to run OOM on the lower zones despite * there being tons of freeable ram on the higher zones). This array is * recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl * changes. */ long lowmem_reserve[MAX_NR_ZONES]; //为各内存与指定若干页面,用于无论如何都不能失败的内存分配
#ifdef CONFIG_NUMA int node; //本Zone所属Node的id #endif structpglist_data *zone_pgdat;//指向对应Node的pglist_data结构体 structper_cpu_pages __percpu *per_cpu_pageset; structper_cpu_zonestat __percpu *per_cpu_zonestats; /* * the high and batch values are copied to individual pagesets for * faster access */ int pageset_high_min; int pageset_high_max; int pageset_batch;
#ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsignedlong *pageblock_flags; #endif/* CONFIG_SPARSEMEM */
/* * spanned_pages is the total pages spanned by the zone, including * holes, which is calculated as: * spanned_pages = zone_end_pfn - zone_start_pfn; * * present_pages is physical pages existing within the zone, which * is calculated as: * present_pages = spanned_pages - absent_pages(pages in holes); * * present_early_pages is present pages existing within the zone * located on memory available since early boot, excluding hotplugged * memory. * * managed_pages is present pages managed by the buddy system, which * is calculated as (reserved_pages includes pages allocated by the * bootmem allocator): * managed_pages = present_pages - reserved_pages; * * cma pages is present pages that are assigned for CMA use * (MIGRATE_CMA). * * So present_pages may be used by memory hotplug or memory power * management logic to figure out unmanaged pages by checking * (present_pages - managed_pages). And managed_pages should be used * by page allocator and vm scanner to calculate all kinds of watermarks * and thresholds. * * Locking rules: * * zone_start_pfn and spanned_pages are protected by span_seqlock. * It is a seqlock because it has to be read outside of zone->lock, * and it is done in the main allocator path. But, it is written * quite infrequently. * * The span_seq lock is declared along with zone->lock because it is * frequently read in proximity to zone->lock. It's good to * give them a chance of being in the same cacheline. * * Write access to present_pages at runtime should be protected by * mem_hotplug_begin/done(). Any reader who can't tolerant drift of * present_pages should use get_online_mems() to get a stable value. */ atomic_long_t managed_pages; //也即 managed_pages 是这个 zone 被伙伴系统管理的所有的 page 数目。 unsignedlong spanned_pages; // 指的是不管中间有没有物理内存空洞,反正就是最后的页号减去起始的页号,即spanned_pages包含内存空洞区域页。 unsignedlong present_pages; //也即 present_pages 是这个 zone 在物理内存中真实存在的所有 page 数目。 #if defined(CONFIG_MEMORY_HOTPLUG) unsignedlong present_early_pages; #endif #ifdef CONFIG_CMA unsignedlong cma_pages; #endif
constchar *name;
#ifdef CONFIG_MEMORY_ISOLATION /* * Number of isolated pageblock. It is used to solve incorrect * freepage counting problem due to racy retrieving migratetype * of pageblock. Protected by zone->lock. */ unsignedlong nr_isolate_pageblock; #endif
#ifdef CONFIG_MEMORY_HOTPLUG /* see spanned/present_pages for more description */ seqlock_t span_seqlock; #endif
int initialized;
/* Write-intensive fields used from the page allocator */ CACHELINE_PADDING(_pad1_);
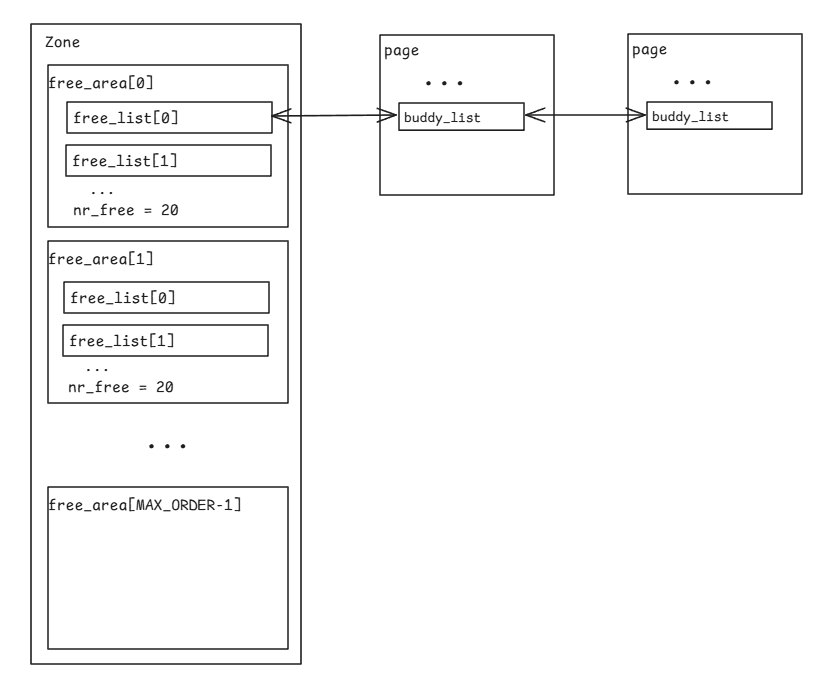
/* free areas of different sizes */ structfree_areafree_area[NR_PAGE_ORDERS];//Buddy伙伴系统的核心数据结构,管理空闲页块链表的数组。
#ifdef CONFIG_UNACCEPTED_MEMORY /* Pages to be accepted. All pages on the list are MAX_PAGE_ORDER */ structlist_headunaccepted_pages; #endif
/* Write-intensive fields used by compaction and vmstats. */ CACHELINE_PADDING(_pad2_);
/* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */ unsignedlong percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* pfn where compaction free scanner should start */ unsignedlong compact_cached_free_pfn; /* pfn where compaction migration scanner should start */ unsignedlong compact_cached_migrate_pfn[ASYNC_AND_SYNC]; unsignedlong compact_init_migrate_pfn; unsignedlong compact_init_free_pfn; #endif
#ifdef CONFIG_COMPACTION /* * On compaction failure, 1<<compact_defer_shift compactions * are skipped before trying again. The number attempted since * last failure is tracked with compact_considered. * compact_order_failed is the minimum compaction failed order. */ unsignedint compact_considered; unsignedint compact_defer_shift; int compact_order_failed; #endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* Set to true when the PG_migrate_skip bits should be cleared */ bool compact_blockskip_flush; #endif
structpage { unsignedlong flags; /* Atomic flags, some possibly * updated asynchronously */ /* * Five words (20/40 bytes) are available in this union. * WARNING: bit 0 of the first word is used for PageTail(). That * means the other users of this union MUST NOT use the bit to * avoid collision and false-positive PageTail(). */ union { struct {/* Page cache and anonymous pages */ /** * @lru: Pageout list, eg. active_list protected by * lruvec->lru_lock. Sometimes used as a generic list * by the page owner. */ union { structlist_headlru;
/* Or, for the Unevictable "LRU list" slot */ struct { /* Always even, to negate PageTail */ void *__filler; /* Count page's or folio's mlocks */ unsignedint mlock_count; };
/* Or, free page */ structlist_headbuddy_list; structlist_headpcp_list; }; /* See page-flags.h for PAGE_MAPPING_FLAGS */ structaddress_space *mapping; union { pgoff_t index; /* Our offset within mapping. */ unsignedlong share; /* share count for fsdax */ }; /** * @private: Mapping-private opaque data. * Usually used for buffer_heads if PagePrivate. * Used for swp_entry_t if PageSwapCache. * Indicates order in the buddy system if PageBuddy. */ unsignedlong private; }; struct {/* page_pool used by netstack */ /** * @pp_magic: magic value to avoid recycling non * page_pool allocated pages. */ unsignedlong pp_magic; structpage_pool *pp; unsignedlong _pp_mapping_pad; unsignedlong dma_addr; atomic_long_t pp_ref_count; }; struct {/* Tail pages of compound page */ unsignedlong compound_head; /* Bit zero is set */ }; struct {/* ZONE_DEVICE pages */ /** @pgmap: Points to the hosting device page map. */ structdev_pagemap *pgmap; void *zone_device_data; /* * ZONE_DEVICE private pages are counted as being * mapped so the next 3 words hold the mapping, index, * and private fields from the source anonymous or * page cache page while the page is migrated to device * private memory. * ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also * use the mapping, index, and private fields when * pmem backed DAX files are mapped. */ };
/** @rcu_head: You can use this to free a page by RCU. */ structrcu_headrcu_head; };
union {/* This union is 4 bytes in size. */ /* * For head pages of typed folios, the value stored here * allows for determining what this page is used for. The * tail pages of typed folios will not store a type * (page_type == _mapcount == -1). * * See page-flags.h for a list of page types which are currently * stored here. * * Owners of typed folios may reuse the lower 16 bit of the * head page page_type field after setting the page type, * but must reset these 16 bit to -1 before clearing the * page type. */ unsignedint page_type;
/* * For pages that are part of non-typed folios for which mappings * are tracked via the RMAP, encodes the number of times this page * is directly referenced by a page table. * * Note that the mapcount is always initialized to -1, so that * transitions both from it and to it can be tracked, using * atomic_inc_and_test() and atomic_add_negative(-1). */ atomic_t _mapcount; };
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */ atomic_t _refcount;
/* * On machines where all RAM is mapped into kernel address space, * we can simply calculate the virtual address. On machines with * highmem some memory is mapped into kernel virtual memory * dynamically, so we need a place to store that address. * Note that this field could be 16 bits on x86 ... ;) * * Architectures with slow multiplication can define * WANT_PAGE_VIRTUAL in asm/page.h */ #if defined(WANT_PAGE_VIRTUAL) void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */ #endif/* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS int _last_cpupid; #endif
#ifdef CONFIG_KMSAN /* * KMSAN metadata for this page: * - shadow page: every bit indicates whether the corresponding * bit of the original page is initialized (0) or not (1); * - origin page: every 4 bytes contain an id of the stack trace * where the uninitialized value was created. */ structpage *kmsan_shadow; structpage *kmsan_origin; #endif } _struct_page_alignment;
structvm_area_struct { /* The first cache line has the info for VMA tree walking. */
union { struct { /* VMA covers [vm_start; vm_end) addresses within mm */ unsignedlong vm_start; unsignedlong vm_end; }; #ifdef CONFIG_PER_VMA_LOCK structrcu_headvm_rcu;/* Used for deferred freeing. */ #endif };
structmm_struct *vm_mm;/* The address space we belong to. */ pgprot_t vm_page_prot; /* Access permissions of this VMA. */
/* * Flags, see mm.h. * To modify use vm_flags_{init|reset|set|clear|mod} functions. */ union { constvm_flags_t vm_flags; vm_flags_t __private __vm_flags; };
#ifdef CONFIG_PER_VMA_LOCK /* Flag to indicate areas detached from the mm->mm_mt tree */ bool detached;
/* * Can only be written (using WRITE_ONCE()) while holding both: * - mmap_lock (in write mode) * - vm_lock->lock (in write mode) * Can be read reliably while holding one of: * - mmap_lock (in read or write mode) * - vm_lock->lock (in read or write mode) * Can be read unreliably (using READ_ONCE()) for pessimistic bailout * while holding nothing (except RCU to keep the VMA struct allocated). * * This sequence counter is explicitly allowed to overflow; sequence * counter reuse can only lead to occasional unnecessary use of the * slowpath. */ int vm_lock_seq; structvma_lock *vm_lock; #endif
/* * For areas with an address space and backing store, * linkage into the address_space->i_mmap interval tree. * */ struct { structrb_noderb; unsignedlong rb_subtree_last; } shared;
/* * A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma * list, after a COW of one of the file pages. A MAP_SHARED vma * can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack * or brk vma (with NULL file) can only be in an anon_vma list. */ structlist_headanon_vma_chain;/* Serialized by mmap_lock & * page_table_lock */ structanon_vma *anon_vma;/* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */ conststructvm_operations_struct *vm_ops;
/* Information about our backing store: */ unsignedlong vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE units */ structfile * vm_file;/* File we map to (can be NULL). */ void * vm_private_data; /* was vm_pte (shared mem) */
#ifdef CONFIG_ANON_VMA_NAME /* * For private and shared anonymous mappings, a pointer to a null * terminated string containing the name given to the vma, or NULL if * unnamed. Serialized by mmap_lock. Use anon_vma_name to access. */ structanon_vma_name *anon_name; #endif #ifdef CONFIG_SWAP atomic_long_t swap_readahead_info; #endif #ifndef CONFIG_MMU structvm_region *vm_region;/* NOMMU mapping region */ #endif #ifdef CONFIG_NUMA structmempolicy *vm_policy;/* NUMA policy for the VMA */ #endif #ifdef CONFIG_NUMA_BALANCING structvma_numab_state *numab_state;/* NUMA Balancing state */ #endif structvm_userfaultfd_ctxvm_userfaultfd_ctx; } __randomize_layout;
/* * If the tree contains a single entry at index 0, it is usually stored in * tree->ma_root. To optimise for the page cache, an entry which ends in '00', * '01' or '11' is stored in the root, but an entry which ends in '10' will be * stored in a node. Bits 3-6 are used to store enum maple_type. * * The flags are used both to store some immutable information about this tree * (set at tree creation time) and dynamic information set under the spinlock. * * Another use of flags are to indicate global states of the tree. This is the * case with the MAPLE_USE_RCU flag, which indicates the tree is currently in * RCU mode. This mode was added to allow the tree to reuse nodes instead of * re-allocating and RCU freeing nodes when there is a single user. */ structmaple_tree { union { //写操作(例如插入、删除 VMA)时通常需要持有这个锁。 spinlock_t ma_lock; //如果本结构体需要加锁则使用这个写锁,读结构一般不加锁,所以可以RCU支持。RCU(read-copy update),指的是要写指针的时候拷贝一份再更新,因此读写不用互斥,仅有写写需要互斥。 lockdep_map_p ma_external_lock; //或者使用外部代码的锁,这里可以忽略。当外部代码(例如 mmap_lock)负责保护整个树时,Maple Tree 就可以复用外部锁的 lockdep 信息,而不用自己的 spinlock。lockdep_map_p 是一个 “lockdep 伪锁” 类型,用来让 lockdep 工具追踪锁顺序,而不实际参与加锁。 }; unsignedint ma_flags; //用于记录树的全局状态与配置选项,至于maple_flags看下面定义 void __rcu *ma_root; //这个是 Maple Tree 的根指针(root pointer),但它是一个 “encoded pointer”(即 maple_enode 类型),带有位域信息。 };
/** * DOC: Maple tree flags * * * MT_FLAGS_ALLOC_RANGE - Track gaps in this tree * * MT_FLAGS_USE_RCU - Operate in RCU mode * * MT_FLAGS_HEIGHT_OFFSET - The position of the tree height in the flags * * MT_FLAGS_HEIGHT_MASK - The mask for the maple tree height value * * MT_FLAGS_LOCK_MASK - How the mt_lock is used * * MT_FLAGS_LOCK_IRQ - Acquired irq-safe * * MT_FLAGS_LOCK_BH - Acquired bh-safe * * MT_FLAGS_LOCK_EXTERN - mt_lock is not used * * MAPLE_HEIGHT_MAX The largest height that can be stored */
/* * The Maple Tree squeezes various bits in at various points which aren't * necessarily obvious. Usually, this is done by observing that pointers are * N-byte aligned and thus the bottom log_2(N) bits are available for use. We * don't use the high bits of pointers to store additional information because * we don't know what bits are unused on any given architecture. * * Nodes are 256 bytes in size and are also aligned to 256 bytes, giving us 8 * low bits for our own purposes. Nodes are currently of 4 types: * 1. Single pointer (Range is 0-0) * 2. Non-leaf Allocation Range nodes * 3. Non-leaf Range nodes * 4. Leaf Range nodes All nodes consist of a number of node slots, * pivots, and a parent pointer. */
/* * Maple State Status * ma_active means the maple state is pointing to a node and offset and can * continue operating on the tree. * ma_start means we have not searched the tree. * ma_root means we have searched the tree and the entry we found lives in * the root of the tree (ie it has index 0, length 1 and is the only entry in * the tree). * ma_none means we have searched the tree and there is no node in the * tree for this entry. For example, we searched for index 1 in an empty * tree. Or we have a tree which points to a full leaf node and we * searched for an entry which is larger than can be contained in that * leaf node. * ma_pause means the data within the maple state may be stale, restart the * operation * ma_overflow means the search has reached the upper limit of the search * ma_underflow means the search has reached the lower limit of the search * ma_error means there was an error, check the node for the error number. */ enummaple_status { ma_active, //指向一个node,可以继续对树进行操作 ma_start, //还没开始搜索树 ma_root, //树已经开始搜索了,但是目前只有一个根节点 ma_none, //树已经开始搜索了,但是目前没有这个节点 ma_pause, ma_overflow, ma_underflow, ma_error, };
/** * mtree_insert_range() - Insert an entry at a given range if there is no value. * @mt: The maple tree * @first: The start of the range * @last: The end of the range * @entry: The entry to store * @gfp: The GFP_FLAGS to use for allocations. * * Return: 0 on success, -EEXISTS if the range is occupied, -EINVAL on invalid * request, -ENOMEM if memory could not be allocated. */ intmtree_insert_range(struct maple_tree *mt, unsignedlong first, unsignedlong last, void *entry, gfp_t gfp) { MA_STATE(ms, mt, first, last);
if (WARN_ON_ONCE(xa_is_advanced(entry))) return -EINVAL;
if (first > last) return -EINVAL;
mtree_lock(mt); retry: mas_insert(&ms, entry); if (mas_nomem(&ms, gfp)) goto retry;
mtree_unlock(mt); if (mas_is_err(&ms)) return xa_err(ms.node);
struct ma_state { struct maple_tree *tree; /* The tree we're operating in */// 指向目标树 unsignedlong index; // 当前操作的起始index(first) unsignedlong last; // 当前操作的终止index(last) structmaple_enode *node;/* The node containing this entry */ unsignedlong min; /* The minimum index - implied pivot min */// 当前节点管理的index区间 unsignedlong max; /* The maximum index - implied pivot max */// 当前节点管理的index区间 structmaple_alloc *alloc;/* Allocated nodes for this operation */// 若需要分配新节点,指向预分配页 enummaple_statusstatus;/* The status of the state (active, start, none, etc) */// 状态机标记(ma_start, ma_none, ma_data等) unsignedchar depth; /* depth of tree descent during write */ unsignedchar offset; unsignedchar mas_flags; unsignedchar end; /* The end of the node */ };
/** * mas_insert() - Internal call to insert a value * @mas: The maple state * @entry: The entry to store * * Return: %NULL or the contents that already exists at the requested index * otherwise. The maple state needs to be checked for error conditions. */ staticinlinevoid *mas_insert(struct ma_state *mas, void *entry) { /* #define MA_WR_STATE(name, ma_state, wr_entry) \ struct ma_wr_state name = { \ .mas = ma_state, \ .content = NULL, \ .entry = wr_entry, \ } 这里进来首先创建一个mas_state上下文, struct ma_wr_state { struct ma_state *mas; // 指向当前 ma_state void *content; // 现有内容(如果已存在) void *entry; // 要插入的新 entry }; */ MA_WR_STATE(wr_mas, mas, entry);
/* * Inserting a new range inserts either 0, 1, or 2 pivots within the * tree. If the insert fits exactly into an existing gap with a value * of NULL, then the slot only needs to be written with the new value. * If the range being inserted is adjacent to another range, then only a * single pivot needs to be inserted (as well as writing the entry). If * the new range is within a gap but does not touch any other ranges, * then two pivots need to be inserted: the start - 1, and the end. As * usual, the entry must be written. Most operations require a new node * to be allocated and replace an existing node to ensure RCU safety, * when in RCU mode. The exception to requiring a newly allocated node * is when inserting at the end of a node (appending). When done * carefully, appending can reuse the node in place. */ wr_mas.content = mas_start(mas); if (wr_mas.content) goto exists; //已存在,不允许重复插入
if (mas_is_none(mas) || mas_is_ptr(mas)) { mas_store_root(mas, entry); //如果是空树,直接在root插入entry returnNULL; }
/* * mas_root_expand() - Expand a root to a node * @mas: The maple state * @entry: The entry to store into the tree */ staticinlineintmas_root_expand(struct ma_state *mas, void *entry) { void *contents = mas_root_locked(mas); enummaple_typetype = maple_leaf_64; structmaple_node *node; void __rcu **slots; unsignedlong *pivots; int slot = 0;
mas_node_count(mas, 1); //确保allocated数量要大于1,不然就多预分配几个 if (unlikely(mas_is_err(mas))) return0;
mas->depth = 1; mas_set_height(mas); ma_set_meta(node, maple_leaf_64, 0, slot); /* swap the new root into the tree */ rcu_assign_pointer(mas->tree->ma_root, mte_mk_root(mas->node)); return slot; }
/* * Leaf nodes do not store pointers to nodes, they store user data. Users may * store almost any bit pattern. As noted above, the optimisation of storing an * entry at 0 in the root pointer cannot be done for data which have the bottom * two bits set to '10'. We also reserve values with the bottom two bits set to * '10' which are below 4096 (ie 2, 6, 10 .. 4094) for internal use. Some APIs * return errnos as a negative errno shifted right by two bits and the bottom * two bits set to '10', and while choosing to store these values in the array * is not an error, it may lead to confusion if you're testing for an error with * mas_is_err(). * * Non-leaf nodes store the type of the node pointed to (enum maple_type in bits * 3-6), bit 2 is reserved. That leaves bits 0-1 unused for now. * * In regular B-Tree terms, pivots are called keys. The term pivot is used to * indicate that the tree is specifying ranges, Pivots may appear in the * subtree with an entry attached to the value whereas keys are unique to a * specific position of a B-tree. Pivot values are inclusive of the slot with * the same index. */
/* * At tree creation time, the user can specify that they're willing to trade off * storing fewer entries in a tree in return for storing more information in * each node. * * The maple tree supports recording the largest range of NULL entries available * in this node, also called gaps. This optimises the tree for allocating a * range. */ structmaple_arange_64 { structmaple_pnode *parent; unsignedlong pivot[MAPLE_ARANGE64_SLOTS - 1]; void __rcu *slot[MAPLE_ARANGE64_SLOTS]; unsignedlong gap[MAPLE_ARANGE64_SLOTS]; structmaple_metadatameta; };
/* * No reference counting needed for current->mempolicy * nor system default_policy */ if (!in_interrupt() && !(gfp & __GFP_THISNODE)) pol = get_task_policy(current);
if (pol->mode == MPOL_PREFERRED_MANY) //当策略允许多个“首选节点”时,跳过后续逻辑,用专门路径分配。 return alloc_pages_preferred_many(gfp, order, nid, nodemask);
if (IS_ENABLED(CONFIG_TRANSPARENT_HUGEPAGE) && /* filter "hugepage" allocation, unless from alloc_pages() */ order == HPAGE_PMD_ORDER && ilx != NO_INTERLEAVE_INDEX) { //分配透明大页,优先从本节点获取 /* * For hugepage allocation and non-interleave policy which * allows the current node (or other explicitly preferred * node) we only try to allocate from the current/preferred * node and don't fall back to other nodes, as the cost of * remote accesses would likely offset THP benefits. * * If the policy is interleave or does not allow the current * node in its nodemask, we allocate the standard way. */ if (pol->mode != MPOL_INTERLEAVE && pol->mode != MPOL_WEIGHTED_INTERLEAVE && (!nodemask || node_isset(nid, *nodemask))) { /* * First, try to allocate THP only on local node, but * don't reclaim unnecessarily, just compact. */ page = __alloc_pages_node_noprof(nid, gfp | __GFP_THISNODE | __GFP_NORETRY, order); //尝试先在本地节点路径上快速分配,不触发内存回收 if (page || !(gfp & __GFP_DIRECT_RECLAIM)) return page; /* * If hugepage allocations are configured to always * synchronous compact or the vma has been madvised * to prefer hugepage backing, retry allowing remote * memory with both reclaim and compact as well. */ } }
/* * This is the 'heart' of the zoned buddy allocator. */ structpage *__alloc_pages_noprof(gfp_tgfp, unsignedintorder, intpreferred_nid, nodemask_t *nodemask) { structpage *page; unsignedint alloc_flags = ALLOC_WMARK_LOW; //低水位线 gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */ structalloc_contextac = { };
/* * There are several places where we assume that the order value is sane * so bail out early if the request is out of bound. */ if (WARN_ON_ONCE_GFP(order > MAX_PAGE_ORDER, gfp)) //防止分配过大的页面 这里指的是大于2^10 returnNULL;
gfp &= gfp_allowed_mask; /* * Apply scoped allocation constraints. This is mainly about GFP_NOFS * resp. GFP_NOIO which has to be inherited for all allocation requests * from a particular context which has been marked by * memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures * movable zones are not used during allocation. */ gfp = current_gfp_context(gfp); alloc_gfp = gfp; if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac, &alloc_gfp, &alloc_flags)) //做一些准备工作,比如确定目标Zone,调整gfp,检查CPUSET相关等。 returnNULL;
/* * Forbid the first pass from falling back to types that fragment * memory until all local zones are considered. */ alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp);
/* First allocation attempt */ page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); //快速路径尝试,最后调用rmqueue() 从伙伴系统取页 if (likely(page)) goto out;
alloc_gfp = gfp; ac.spread_dirty_pages = false;
/* * Restore the original nodemask if it was potentially replaced with * &cpuset_current_mems_allowed to optimize the fast-path attempt. */ ac.nodemask = nodemask;