Personal works
Secure AI Systems: A Layered Perspective
My Ph.D. research focuses on AI system security, from high-level application risks, through AI framework-level vulnerabilities, to low-level hardware exploitation. This layered exploration reveals systemic threats that span across the full AI software stack.
🧩 Layer 1: Application-Level — Python Module Conflicts
Paper: ModuleGuard: Understanding and Detecting Module Conflicts in Python Ecosystem (ICSE 2024)
Link: DOI: 10.1145/3597503.3639221
Python has become the most important language for AI development. However, the ecosystem suffers from module conflicts (MCs), where different packages accidentally override or confuse module imports. These conflicts can cause runtime failures and make model deployment errors.
- Module overwriting at install time
- Import confusion at runtime
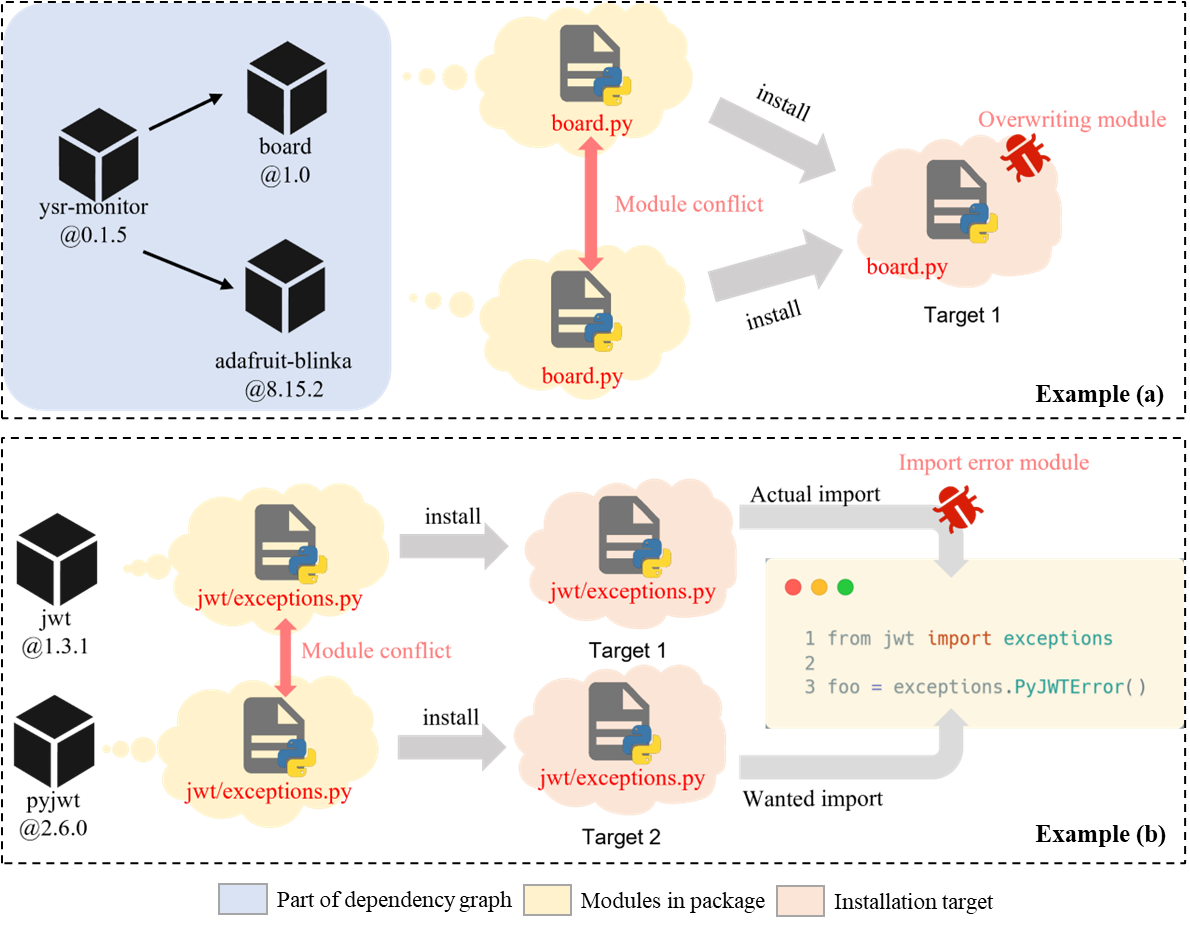
We systematically studied MCs across 4.2M PyPI packages and 3.7k GitHub projects. Our tool ModuleGuard leverages semantic-aware static analysis and installation simulation to detect:
🔧 We proposed
ModuleGuardand analyzed the ecosystem at scale, uncovering thousands of silent module-level module conflict issues in real-world projects.
🧠 Layer 2: Framework-Level — Framework’s API-based Malicious Models
Paper: My Model is Malware to You: Transforming AI Models into Malware by Abusing TensorFlow APIs (S&P25)
Link: GitHub: TensorAbuse
Model sharing enables innovation — but also risk. We proposed the TensorAbuse attack, which abuses legitimate TensorFlow APIs (like tf.io.matching_files, tf.raw_ops.DebugIdentityV3) to:
- Read arbitrary files
- Leak IPs
- Send data to external servers
- Get shell

These attacks are embedded in the model graph, and get executed silently during inference — Users cannot be aware of them.
🚨 We found 1,083 persistent TensorFlow APIs. 20 APIs in them can be abused to cause malicious behaviours. None of the current model hubs (e.g., Hugging Face, TensorFlow Hub) or scanners (e.g., ModelScan) could detect our synthetic malware.
🔍 Layer 3: Hardware-Level — GPU ASLR Weakness
Paper: Demystifying and Exploiting ASLR on NVIDIA GPUs
Status: Under submission
Modern AI workloads run on GPUs, but their memory layout is opaque. We reverse-engineered NVIDIA GPU’s ASLR implementation, uncovering multiple critical flaws:
- GPU heap is entirely unrandomized
- Correlated offsets between GPU and CPU ASLR undermine both
- Some regions are shared across all CUDA processes, enabling covert channels
We built two tools:
- FlagProbe to recover memory segment semantics
- AnchorTrace to trace randomized addresses recursively and infer ASLR entropy
🧪 We showed that GPU memory layout leaks can be exploited to infer CPU glibc addresses — undermining fundamental ASLR protections.

📫 Contact
If you’re interested in collaboration, feel free to reach out:
- 📧 Email: zhuruofan@zju.edu.cn
- 🔗 GitHub: ZJU-SEC