HyperFuzzer:An Efficient Hybrid Fuzzer for Virtual CPUs
HyperFuzzer: An Efficient Hybrid Fuzzer for Virtual CPUs
contribution
- The first efficient hybrid fuzzer for virtual CPUs without using a slow hardware emulator.
- The Nimble Symbolic Execution technique that enables whitebox fuzzing for virtual CPUs with only a control-flow trace recorded by the commodity hardware.
- An effective prototype of HyperFuzzer that has found 11 previously unknown virtual CPU bugs in the Hyper-V hypervisor.
motivation
这篇paper以一个hyperfuzzer找到的bug来解释动机。这个bug发生在16bit 保护模式下的情况,并且没有页面保护的时候,VM试图执行一个APIC的MMIO区域的指令,该指令被map在物理地址0xFEE00000位置,随后会trap进入hypervisor模拟该指令,在这种情况下,hypervisor发现VM处于16bit情况下,于是会把前面的物理地址转为低16位,即0x0000,从而发生bug。这主要是由于hypervisor无法理解在x86上16bit实模式和16bit保护模式的区别。16bit实模式和保护模式的有效数据地址都是16bit,然后指令指针在实模式下是16bit,在保护模式下是32bit。(这种差异在手册中也没有详细说明)。
为了找寻这种bug,从而开发了hyperfuzzer,并且提出了两个requirements:
- 必须mutate一个VM entire state,而不是仅仅是它运行的指令。这是由于有些状态定义了vm的模式状态,就比如上面bug所说的16bit保护模式,这些状态是被GDT中的两个bit位控制的。
- HyperFuzzer必须支持基于动态符号执行的精确输入生成。为了在16位保护模式下生成新的虚拟机状态,HyperFuzzer需要对guest GDT中的2位进行反置。这要求它精确地跟踪虚拟机管理程序检查guest VM模式时的路径约束。
overview
thread model
假设攻击者能够完全控制guest VM,并且能够控制虚拟硬盘,由此可以控制boot的代码以及guestOS。
hyperfuzzer’s design
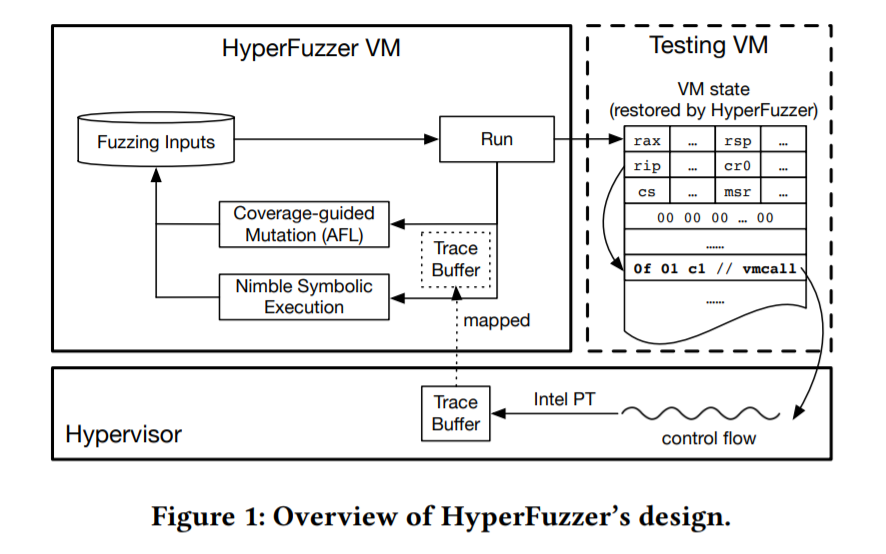
Inputs就是一个完整的VM state,即一些寄存器状态,一些即将运行的指令以及这些指令运行的上下文环境。
每个input loop会在hyper-V的一个VM中运行,这些VM会触发VCPU的执行,然后可能会暂停VM 触发一个陷入到hypervisor。在这个过程中,hyperfuzzer利用Intel PT等硬件特性去记录控制流。
Design
fuzzing setup
输入模型:将 VM 完整状态作为 fuzzing input
- 传统的 fuzzing 通常把“指令”、“参数”或“系统调用”作为输入来变异。HyperFuzzer 的 insight 是:虚拟 CPU 的行为主要由虚拟机状态(VM state,包括寄存器、内存、控制结构等)决定。
- 因此每个 fuzzing 样本是一个 VM 的完整状态快照(或者说足够完整以使得 hypervisor 在第一次 VM 退出时可以执行)。通过变异该状态,既可以变异要执行的指令,也可以变异周围的架构环境(例如段寄存器、页表、控制寄存器等)。
- 为了效率,HyperFuzzer 并不要求 snapshot 包含冗余无用状态,而是精简到“架构上必须的那部分”(例如页表只有在必要时候才包含等)。这样输入体积可以压得很小(几百字节级别),便于快速变异与恢复。
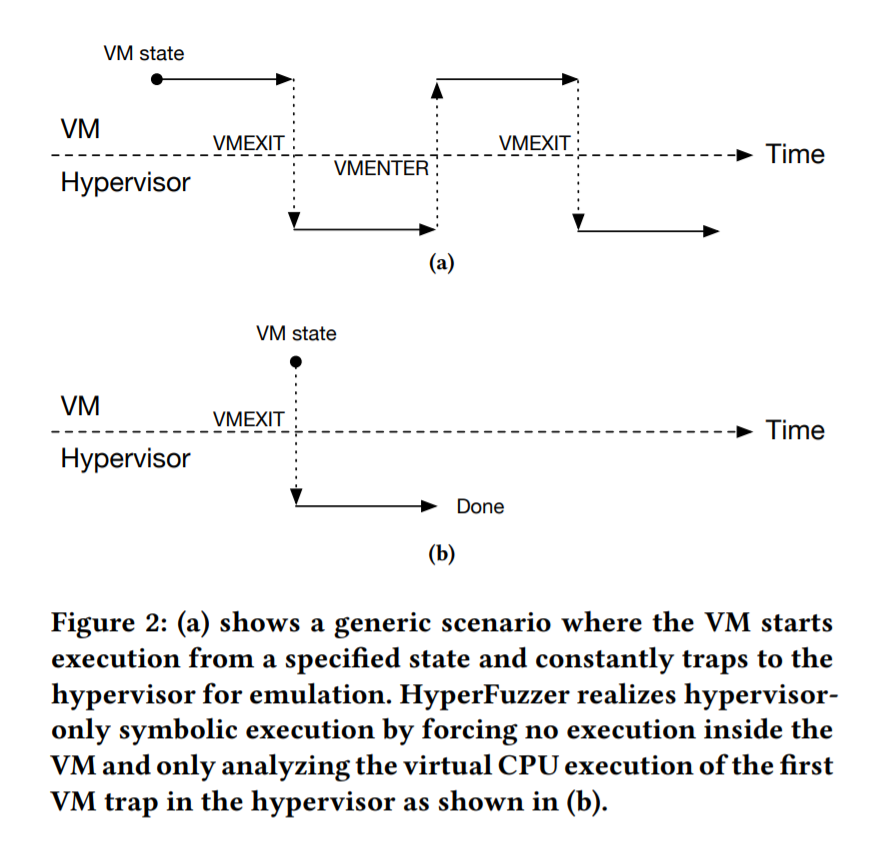
Fuzzing 运行方式:只触发第一个 VM trap
- 为了简化分析,HyperFuzzer 设计让 VM 在恢复后 立即触发一次 VM 退出(VMEXIT),即 guest 执行一条特殊指令或者通过单步强制退出,以便 hypervisor 介入。然后抓取这次退出进入 hypervisor 的控制流执行,处理完这次退出之后就停止该执行。即只 fuzz “单次 trap 进入 hypervisor 的这条路径”。
- 这样做的好处是:
- 避免在 guest 中做大量执行与符号追踪(减少复杂性)
- 每次测试的路径较短,使得符号执行、约束求解更加可控
- 避免在 guest 中做大量执行与符号追踪(减少复杂性)
- 虽然看似只能覆盖一次 VMEXIT 的代码路径,但论文认为:因为你可以对 VM 状态做变异,不同的状态就可能触发 hypervisor 内不同的分支/退出行为,从而整体可以探索较为全面的 vCPU 实现。
Nimble Symbolic Execution(NSE):用低开销控制流 + 重构近似执行轨迹
- 传统的符号执行(白盒分析)需要详尽的执行轨迹(control flow + data flow)记录。但这样会带巨大的开销,尤其是在 hypervisor 级别。HyperFuzzer 不记录完整数据流,仅借助硬件跟踪机制(如 Intel Processor Trace, PT)来记录 控制流,即指令/分支走向(不记录寄存器或内存具体值)
- 然后,通过已知的 fuzzing input(即 VM 状态)+ 控制流记录,在用户态重构一个“近似”的执行轨迹,在这个轨迹上做符号执行、路径约束处理,生成新的输入。这个过程就是论文称的 Nimble Symbolic Execution (NSE)。
- 在重构过程中面临两大挑战:
\1. 缺失内部未知状态:hypervisor 内部可能有一些状态在控制流记录里不可见(例如超内核内部状态、缓存、内部指针),这些状态若被用到路径约束或决定 memory 地址,会影响符号执行。论文通过“占位赋值”(给未知内存/寄存器赋一个任意合法具体值)在多数情况下规避问题;并指出在 CPU 虚拟化场景下约 98% 的路径判断不依赖这些未知内部状态。
\2. 隐藏硬件检查 (hidden hardware constraints):硬件在做 VMEXIT 前会对 VM 状态做一些验证、检查(这些在 hypervisor 代码里不可见),这些检查不在控制流里也不会被符号执行捕获。若生成的新输入违反这些硬件检查,则硬件可能拒绝进入 hypervisor。论文为此做了两方面缓解:
- 对符号变量做按位建模,防止在求解新输入时无意间破坏那些硬件已有的约束(比如某个 bit 一定要为 1)
- 应用 “无关约束消除”(unrelated constraint elimination)技巧:在构造 path constraint 时,移除与欲翻流程分支无关的符号变量或约束,以减少可能引入与硬件检查冲突的改动。
混合机制:覆盖导向 + 符号指导结合
- HyperFuzzer 的 fuzzing 循环融合了灰盒变异 (coverage-guided mutation, 如 AFL) 和 白盒输入生成 (通过 NSE) 两部分。对于进入新 coverage 的样本,会交给 NSE 去生成新的输入;新输入再执行、判断是否扩展 coverage。
- 为了效率,只有一部分样本(“interesting inputs”)才会被送去 NSE 符号处理,而非所有样本都做符号执行,从而节省资源。