内存管理
内存管理
内存管理的主要功能有
- 内存空间的分配与回收
- 地址转换
- 内存空间的扩充
- 内存共享
- 存储保护
程序的链接与装入
用户程序在磁盘上存储形式为二进制文件,当执行程序时,其会被调入内存,并组织成进程的形式。通常这一过程需要以下几个步骤:
预处理:将用户源代码中的头文件和宏等进行替代,删除所有注释等等一系列操作
编译:由编译器将用户源代码编译成汇编文件,并汇总所有符号。main.c->main.S
汇编:将汇编文件(.S文件)根据特定平台等生成二进制文件,即将指令翻译成二进制形式,并合并符号表等。main.S->main.o,其中.o文件称为目标对象模块。
链接:由链接器将目标对象模块和若干库函数链接在一起,形成一个完整的加载模块,生成可执行文件。需要进行符号解析和地址重定位。链接有三种方式:
装入:将可执行文件载入内存运行。
而程序的符号地址绑定可以分为三部分确定:
- 在编译时确定:如果编译时候就知道进程将在内存驻留的地址,那么就可以生成绝对地址,在MS-DOS系统上的.COM格式文件就是如此。
- 在加载时确定:如果编译时候不知道,则编译器会产生可重定位代码,其地址绑定会延迟到加载时候进行。
- 在执行时确定:进程执行时候可以从一个内存段转移到另一个内存段,此时地址绑定需要执行时候才能确定,大多数操作系统采用这种办法。
程序链接的三种形式
程序的链接也有三种形式:
静态链接:在程序运行前需要将各个模块和库函数组装在一起,形成一个完整的模块,而每个模块内部的符号都是从0开始的相对地址,装成一个大模块时需要对其进行修改;同时一些模块会向外部提供调用接口,也需要将外部调用符号转变为相应的相对地址。
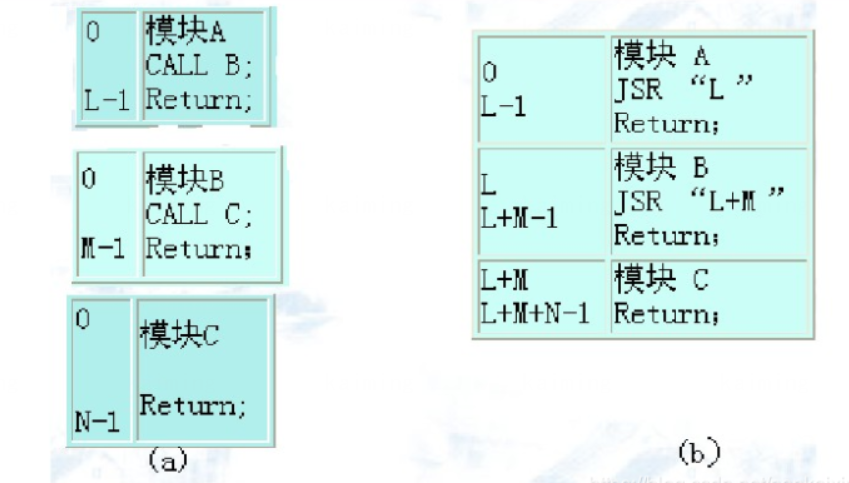
装入时动态链接:将用户源程序编译后得到一组目标模块,在装入内存时候采用边装入边链接的方式,即在装入时若发生一个外部模块调用,将引起装入程序去找出相应的外部目标模块,并将它装入内存,还要修改目标模块中的相对地址。其优点是便于修改和更新,便于实现对目标模块的共享。
虽然前面所介绍的动态装入方式,可将一个装入模块装入到内存的任何地方,但装入模块的结构是静态的,它主要表现在两个方面:一是在进程的整个执行期间,装入模块不改变;再者是每次运行时的装入模块都是相同的。实际上,在许多情况下,每次要运行的模块可能是不相同的,但由于事先无法知道本次要运行哪些模块,故只能是将所有可能要运行到的模块,在装入时全部链接在一起,是每次执行时的装入模块是相同的。显然这是低效的。因为这样,在装入模块的运行过程中,往往会有某些目标模块根本就不运行。比较典型的例子是错误处理模块,如果程序在整个运行过程中,都不出现错误,便不会用到该模块。对某些目标模块的链接,是在程序执行中需要该模块才进行的,凡在执行过程中需要的模块会被调入内存,链接到装入模块上,其能节省大量内存空间,因为不需要的部分都不会被加载入内存。
执行时动态链接:可将某些目标模块的链接,推迟到执行时才进行。即在执行过程中,若发现一个被调用模块尚未装入内存时由OS去找到该模块,将它装入内存,并把它连接到调用者模块上。
做个比喻就是,静态链接就好像机关枪,把所有子弹都装好,然后突突突,但是所耗费很大空间,很笨重。而装入时动态链接就好像子弹先装入弹夹中,装入使用的时候把弹夹装上枪,然后开始执行,虽然小巧了很多,但是很多错误处理的代码等等还是会被加载入内存。执行时动态链接就好像一把老式kar98,每次要狙人开枪的时候,装入一颗子弹,节约了很多空间。
程序装入的三种方式
在将程序装入内存时也有三种形式:
- 绝对装入:只适用于单道程序环境,在编译时就知道程序所在的内存位置,于是生成的是绝对地址的目标代码,其程序中的逻辑地址与真实的物理地址相同。
- 可重定位装入:在多道程序环境下,多个目标模块的起始地址通常从0开始,程序中的其他地址都是相对于起始地址的。在装入时对目标程序中指令和数据地址的修改过程称为重定位。
- 动态运行时装入:程序如果发生移动,则需要动态装入方式,装入程序把装入模块放入内存后并不立即把装入模块的地址转化成绝对地址,而是在程序真正要执行时候才真正转化,该种方式需要硬件上有重定位寄存器支持。优点是可以将程序分配到不连续的存储区,在程序运行之前可以只装入部分代码即可运行,然后在程序执行期间,根据需要动态申请内存,也便于程序段共享。
进程的内存布局
如图所示是一个进程在内存中的映像,64位和32位有所不同,但是大差不差。
miscellaneous(杂项)
其中比较关键的是由上图可以看到系统会把进程的ELF文件(ELF文件长啥样就谷歌搜,一大堆图)去掉header之后装入了地址为0x40000000的位置处,肯定有人会问为什么是这个地址。emmm很多网上资料都没讲清楚。
首先,为什么前面要有一段空洞,不论是32位还是64位,主要是为了防止NULL POINTER被访问的问题,这样做0地址就是一个非法地址,访问时能被操作系统捕获。但是有人肯定会问,为什么不能装载在虚拟地址为1处?其实也是可以的,但是操作系统一般会为了分页方便,就前面空出一部分空间,这个空出的多大空间不是固定的,至少我测了三种环境下(QEMU跑的64位linux,腾讯云服务器,双系统的物理主机上的linux)都是不一样的。其中一部分原因是开启了ASLR的缘故,但是我关了之后还是不一样的。(网上有人是0x400000,换算下来是4M,说是因为Linux分页机制,有些页面是大页,不是4K大小,所以就开得大点,保证一页装不下。这种说法我不确定是否正确)。
网上很多图针对于32位的地址空间会说前面128M是空洞(我手上没有32位机器,没法去验证,至少64位我验证了。其次我也不明白为什么32位要开128M那么大,像64位这样开小点不行吗?)
还要说的一点是linux是通过mmap将elf文件载入内存的,而Linux对mmap可映射的地址范围做了限制,由变量MMAP_MIN_ADDR(该值一般为65532,可以通过命令cat /proc/sys/vm/mmap_min_addr查看)限制,也就是说装载的地址首先要求不能小于这个值,否则无法mmap。其次这个映射的基质是由链接器中的一个变量定义的(网上一篇blog说的,我也不知道正确不正确,我记得他说在一个文件名为elf_x86_64xxx的文件里)。
内存各个部分含义
- .text:其中
.text段为代码段,用以存储包括_init等初始化函数在内的程序片段。 - .rodata:用以存储只读数据,包括一些字符串什么。而且同样的字符串只会在其中保存有一个副本,所以当创建两个指针指向两个一样的字符串时候,这两个指针的值是一样的。
- .data:用以存储读写数据,包括已初始化不为0的全局变量和静态变量。
- .bss:用以存储初始化为0的全局变量和静态变量。
内存分配方式
内存分配方式有很多种,包括连续内存分配,分段,分页,段页式等等。
连续内存分配
内存保护
为了防止进程访问不属于自己的空间,可以采取两种方式进行内存保护:
- 在CPU中设置上下限寄存器,用以存储存放用户进程在主存中的上界和下界,从而防止内存读取越界。
- 在CPU中设置重定位寄存器和界限寄存器,当CPU访问地址的时候和界限寄存器进行比较,判断是否在可访问范围内。其中重定位寄存器存储最小的物理地址,界限寄存器存储最大的逻辑地址。
内存分配
最简单的分配方式为多分区方法:将内存分为多个固定大小的分区,每个分区包含一个进程。该种方法现在已经不再使用。
随后衍生出的是可变分区法:操作系统中有一个表记录哪些内存可用,哪些内存不可用。最开始内存为一整块空闲,当一个用户进程来之后,操作系统根据内存需求和现有内存使用情况进行分配,决定哪些进程可以被分配内存空间,然后这些进程进入内存开始竞争CPU,这些进程运行结束后释放内存空间,操作系统回收这部分内存。 这种方法会导致内存中存在很多空洞和碎片。
动态存储分配问题及算法
根据一组空闲孔来分配大小为n的请求问题为动态存储分配问题,一般可以通过首次适应,最优适应和最差适应的方法分配。
- 首次适应:分配首个足够大的孔。
- 邻近适应:也是分配首个足够大的孔,不过和首次适应的区别在于首次适应是每次从链表头开始查找,而邻近适应每次从上次查找结束的位置开始查找。
- 最优适应:分配最小足够大的孔。
- 最差适应:分配最大的孔。
分段
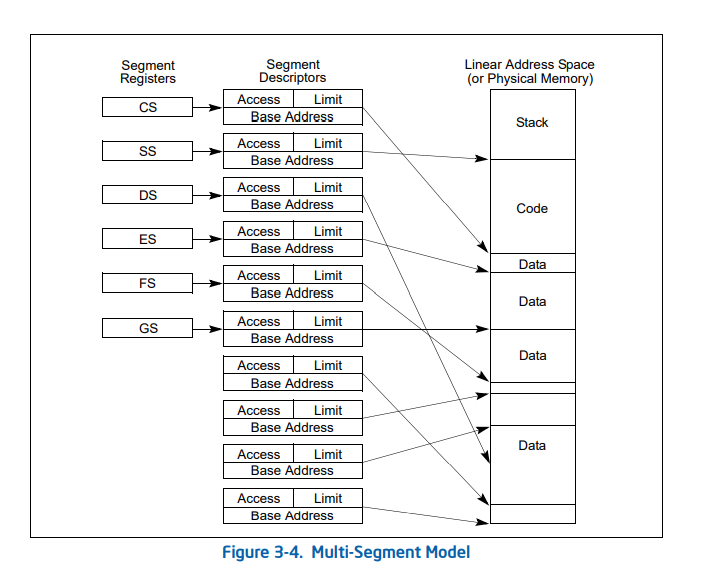
分段管理方式提出考虑了程序员和编程视角,由于用户的内存视图和实际物理内存不一样,但是分段提供了一种方式,将程序员的视角映射到实际的物理内存,这样系统可以更自由地管理内存,程序员也有一个更自然的编程环境。
程序员不再认为内存是一个字节的线性数组,而是看做不同长度的段。因为程序员更关心堆栈,数学库,主程序等名词,而不关心这些元素所在的位置,他也并不关心堆栈放在主程序之前还是之后。由此逻辑地址空间便是由一组段组成的,每个段有自己的名称和长度,逻辑地址是段的名称和段内偏移组合。
图为分段机制的程序员视角。
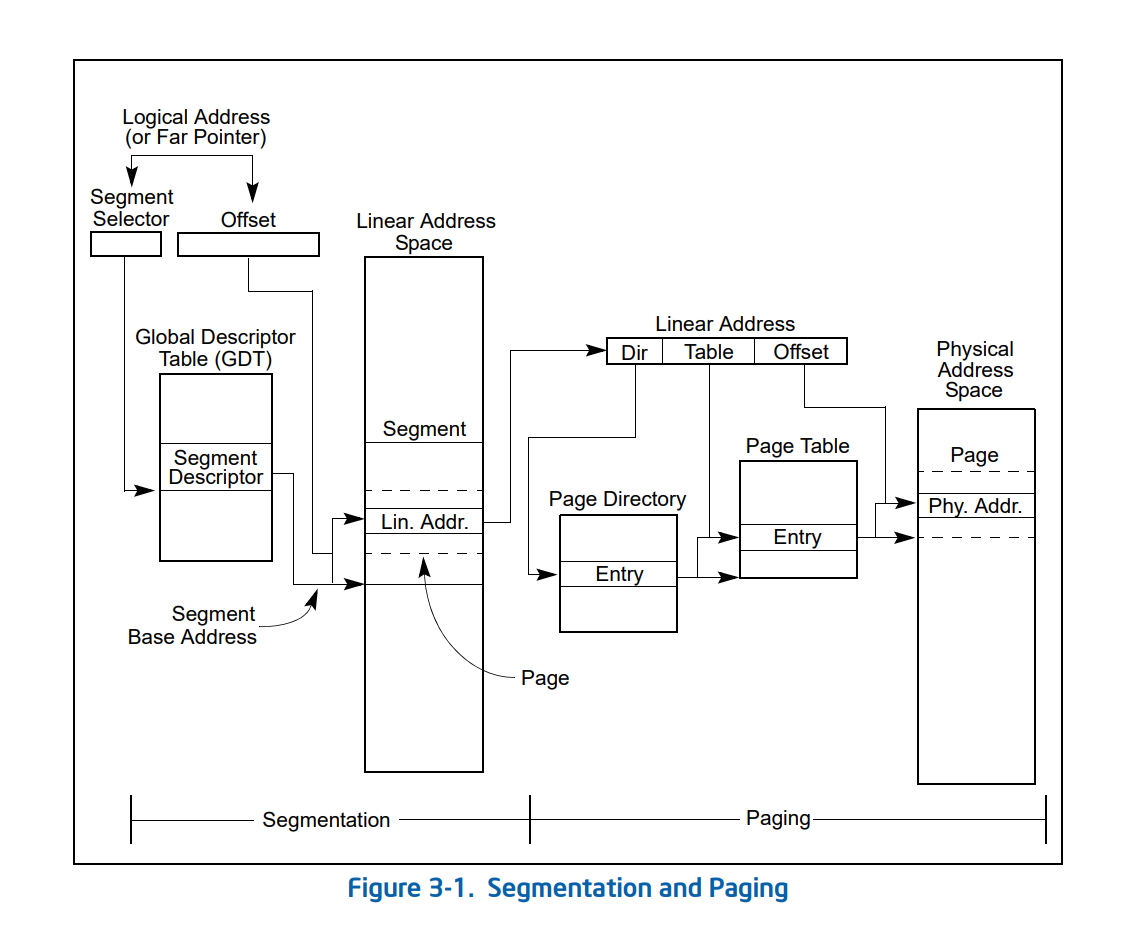
分段的硬件支持
16位
硬件上x86在实模式和保护模式中有所不同。在实模式中寄存器都是16位的,而CPU提供四个段寄存器CS,DS,SS,ES,于是寻址方式为,可以最多访问2^20^大小内存:
1 | 物理地址 = (段寄存器 << 4) + (ip寄存器(偏移量)) |
32位
但是到了32位保护模式,CPU变成了32位,同时变成了6个段寄存器,多了FS和GS,可是为了兼容16位程序,其寄存器大小还是16位,于是之前的模式无法满足32位的寻址了。于是Intel增加了两个寄存器:GDTR(全局描述符表),LDTR(局部描述符表)寄存器,新增的寄存器为32位,记录了表的基址。表中每个表项占8个字节(寄存器只有2个字节,所以只能将表放在内存中),其中记录了段的基址和段界限,而相应的CS,DS,SS,ES中存放的是段描述符的索引值。
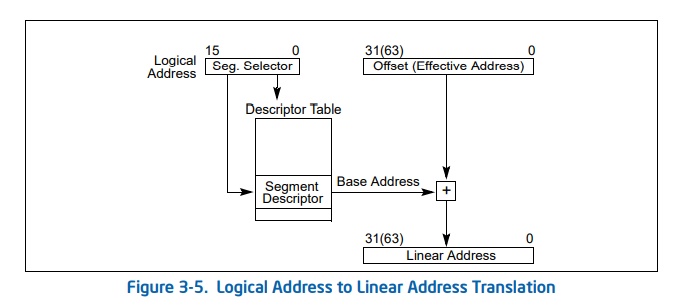
说到gdtr寄存器和ldtr寄存器,就来说说全局描述符和局部描述符的区别吧,一般来说全局描述符整个系统中只有一个,其中也存了很多ldt描述符表的基址作为表项(因为理论上来说ldt表也是一段内存,也可以认为是一个段),而给每个任务分配一个ldt表,任务切换的时候切换ldtr寄存器,gdtr寄存器不变,由此每个任务可以由自己的代码段堆栈段等,而全局描述符表中除了存储内核的堆栈段等段,还要存储所有任务的局部描述符表段。
用网上的图吧,该图吧描述符的格式和段寄存器的格式也标明了。
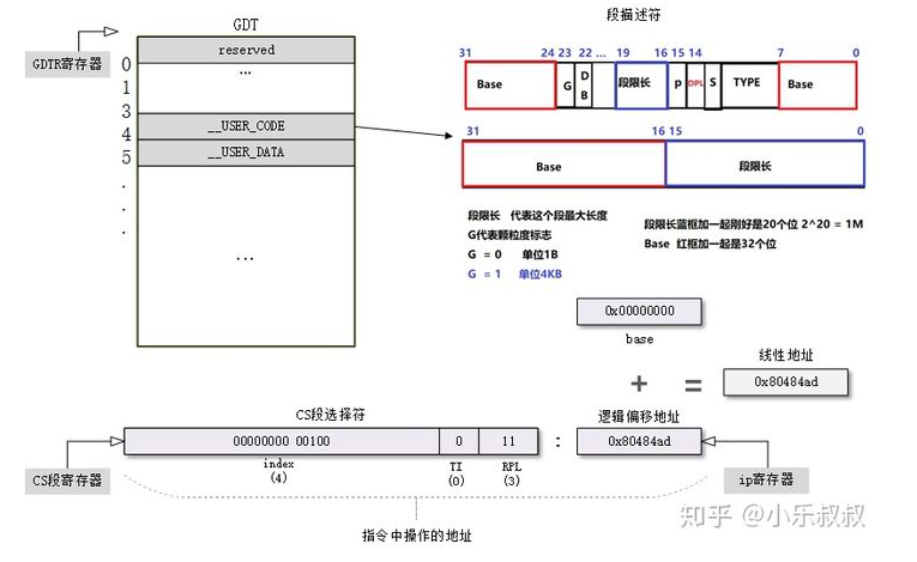
而linux系统在段描述符表中把所有的段基址都设为了0x0,即平坦内存模型,linux中只有一个段。
64位
在64位模式下:处理器把CS/DS/ES/SS的段基都当作0,忽略与之关联的段描述符中的段基地址。因为在64位模式中,CPU可以访问所有可寻址的内存空间。今天大多数的64位CPU只需要访问40位到48位的物理内存,因此不再需要段寄存器去扩展。
分页
分段允许进程的物理地址空间非连续,而分页是另一种提供这种优势的方案。且分页能够避免外部碎片和紧缩,分段不可以。除此之外分页更有利于内存块交换到交换空间。
硬件支持
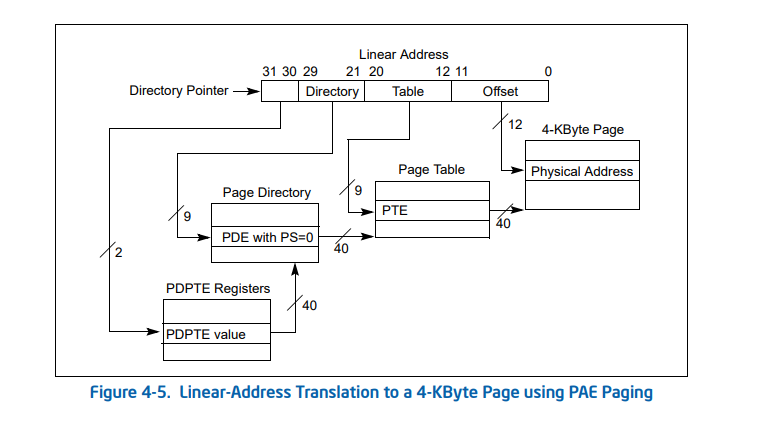
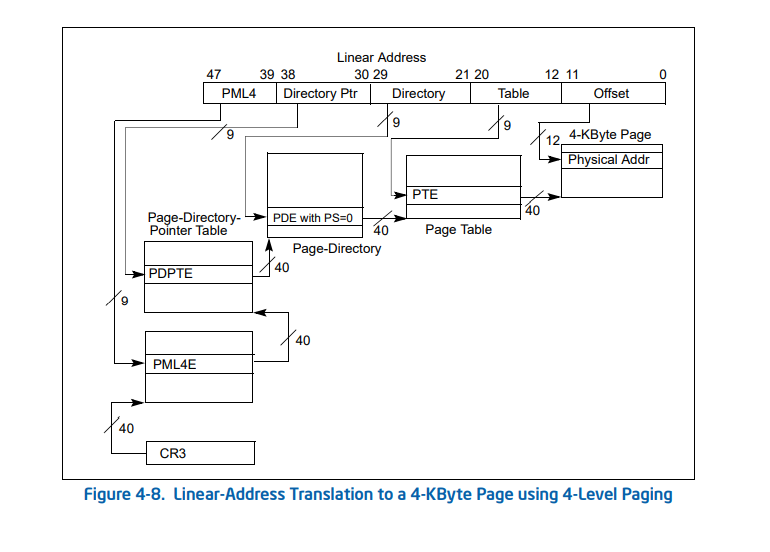
都耳熟能详了,CR3,MMU那一套呗贴几张图把。
32位
64位
段页式内存管理
将分段和分页结合的方式,也耳熟能详了吧,也贴一张图就完了。