V-Shuttle:Scalable and Semantics-Aware Hypervisor Virtual Device Fuzzing
V-Shuttle: Scalable and Semantics-Aware Hypervisor Virtual Device Fuzzing
2.背景知识
2.1 虚拟设备
所谓虚拟设备,就是提供给guest的外围仿真设备。guest中的驱动可以处理这些虚拟设备,就好像他们处理物理设备一样。每一个设备的协议规定了寄存器级别的硬件接口,用以设备和os之间的交互。总的来说虚拟化设计虚拟设备是根据SPEC来设计的,但是这会提供一种攻击hypervisor的方式。
2.2 驱动与设备交互
总的来说,一个虚拟设备暴露了三种重要的交互方式,MMIO,PIO,DMA(IOMMU)。(这三个就不细说了,具体原理看王柏生、谢广军撰写的《深度探索Linux系统虚拟化:原理与实现》一书第三章)。
在最开始设备执行的时候,guest的驱动会写入一些数据到MMIO或者PIO regions,从而做一些初始化相关的工作,比如设置设备状态,寄存器地址初始化等等。完成初始化之后,设备进入ready状态,可以进行处理交互数据。最初始的数据交互机制是DMA,它允许设备和guest之间交换大量复杂的数据。由于数据处理部分是设备驱动的主要code part,所以这一部分也比别的部分更加危险,更容易受攻击。
2.3 核心挑战-嵌套的结构体
hypervisor是被用于guest memory和设备驱动交互的。这种转换操作是用特定的和DMA相关的API,比如QEMU里的pci_dma_read 和pci_dma_write。pci_dma_read从guest的内存复制了一个block的数据到host的buffer,write则相反。通过指定的地址参数,DMA操作可以访问任意位置的guest的物理内存。
我们观察到通过DMA的机制访问的一些数据结构通常被组织成nested structures。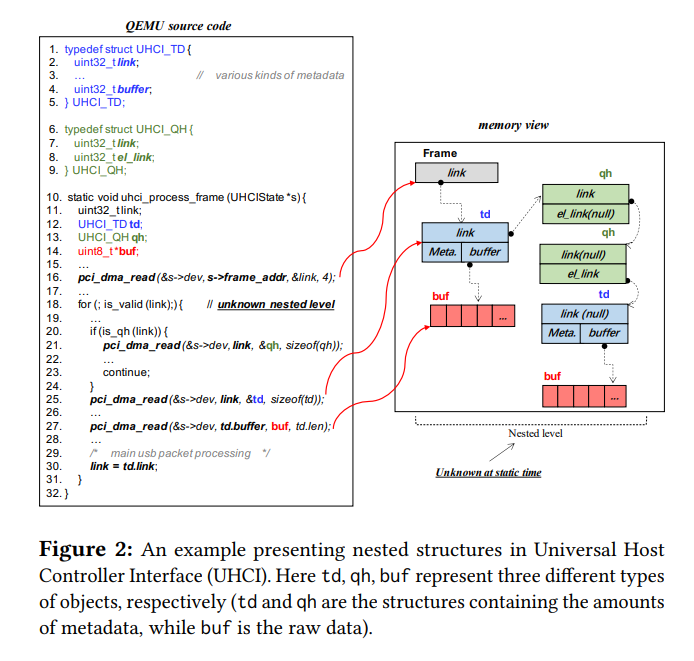
如图。这些结构体有很多种类和很多层,所以hypervisor通过树形结构组织这些structure,这些structure开始于一个root node。这些特定导致fuzz的一些问题:
1)Nested Form Construction。
对于fuzz来说,构建复杂的多层数据对象于结构,或者子结构是很困难的,因为这些对象可以是任意层次的。其一,数据的分层结构,树的相互嵌套等等导致的复杂,fuzz方法很难构造这种数据;其二,每个node内部的指针和数据的偏移也不是固定的,而fuzz mutator会把这些node一视同仁,从而导致不容易变异数据。并且也由于缺少数据语义(semantics),更导致了fuzz的困难。
2)Node Type Awareness。
由于设备根据规范支持各种数据类型,因此需要关于嵌套节点的细粒度语义知识。不同node之间的连接也是尤为重要,有些连接是固定的,所以需要我们在node之中建立正确的连接方式。有些指针关系甚至可能在运行时候才知道,因为很多field可以指向不同种类的数据。所以在node level,fuzzer需要知道具体的指针语,从而能够构造正确的数据结构,进入深层次的fuzz,而不是在程序开始阶段就导致crash。
为了更好的说明这些nested structure是如何被hypervisor支持的,接下来讲一些hypervisor处理nested structure的通常情况。
1)从root节点开始,hypervisor开始获得了一个指针(一般由address register获得),该指针指向一个处理guest memory中的数据结构 A。
2)hyervisor动态地allocate buff,该buff是用以存储A的副本。
3)hypervisor 通过pci_dma_read拷贝A到buff中。
4)当A中有指针指向别的结构B的时候,hypervisor用同样的方法,构造一个副本B的buff。
5)再次利用pci_dma_read拷贝B到buff中。
如此反复,从而递归地获取一个structure。然后用上图做一个例子。
一个直观地方法来处理这些数据结构就是用structure-aware fuzzing。这些方法需要开发者构造一个规范的模型。并且还需要把这些数据结构连接起来,所以会很费时,并且还容易出错。并且这些数据结构的SPEC也很庞大,需要大量工作来定义。手工的工作也很容易出错。并且开发人员可能会增加新的机制,因此这些方法都不太适合大范围的hypervisor fuzz。
3. V-SHUTTLE DESIGN
V-shuttle是一个轻量级的,可度量的,语义感知的hypervisor fuzz framwork,并且结合了civerage-guided fuzz和静态分析。为了定位前面所说的challenge, V-shuttle用了两种方法:1)重定向DMA相关的函数。2)通过seedpools的语义感知fuzz。
3.1 Threat model
假设攻击者是一个privileged guest user,同时拥有VM内的所有内存权限,由此可以向device输送二进制数据。
3.2 System overview
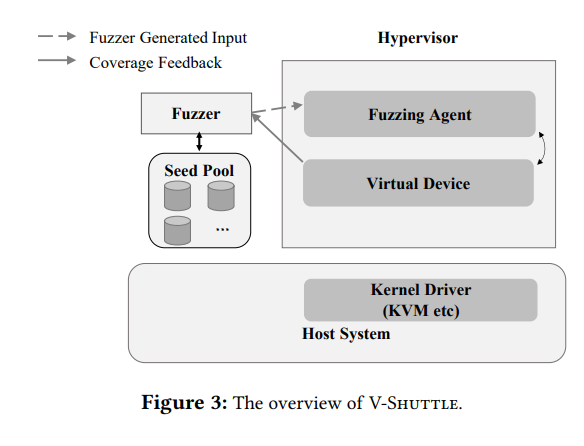
它利用集成在hypervisor中的fuzz代理,向虚拟设备喂测试数据,持续向虚拟设备发送读写请求。主要由两部分,fuzzer和fuzzing agent。
fuzzer
fuzzer在hypervisor之外,并且启用持久模式,即不用每次测试都新启动一个新的实例。因为1)重启一个hypervisor进程或者恢复一个快照是有开销的。2)hypervisor是event-based system,它设计的目的就是长时间的交互。并且大多数的BUG是通过对已发现的分支进行深层次的fuzz发现的,这些深层次状态很可能依赖于之前很多状态的交互构建出来的。
fuzzing agent
它是被放置在hypervisor中的核心组件。1)驱动fuzzing loop和(fuzzer 和 device)的交互 。2)管理DMA/MMIO 的上下文分配。为了适应传统的application-fuzz的方法。把guest system中的数据交互重定向到了fuzzed input中。然后fuzzing agent模拟攻击者控制的恶意guest kernel driver,拦截所有device发出的DMA和IO 读写指令,所有从hypervisor的读写操作都被发送到了一个fuzzing agent中的注册函数里。该注册函数会执行操作并返回fuzz生成的数据给device。所以增加新设备的时候,没必要额外的labor,因为它是嵌入在hypervisor中的。
3.3 DMA 重定向
由于给大量的device创建合法的数据结构工作量很大,并且很复杂,所以设计了DMA重定向的方法。通过拦截设备请求guest memory,来扁平化嵌套结构。他把DMA传输转化成fuzz input的读取,即把所有的DMA相关的API中以及他们的包装函数中都插入宏,从而所有的API都被替换成从文件中读取数据,从而是读取fuzzing input。下图给了个例子。

而关注于DMA是因为他们负责guest和host之间的数据交互,也是构建这些嵌套数据结构的关键机制。同时这样也消除了DMA的寻址操作。并且由于完全控制DMA机制,任何的DMA请求都能够用传统coverage-guided fuzzer,不论数据结构中的指针指向哪里,即使他们是0. 从图上可以看出原本需要buffer_addr,现在只需要从文件中读取,所以任意地址都行。并且V-shuttle只是操作设备从guest中读取的数据,并不管写入的数据,因为一般来说攻击者都是向设备来input一些数据来攻击的,所以不管他们收到的。
当收到device向guest memory中的read 请求:
1)V-thuttle确保DMA读取函数调用源自于正在监视的目标设备,因为对其他来自系统组件的DMA传输请求不感兴趣,这些请求不受guest控制。
2)给定的host 的buffer和 buffer size,V-shuttle从seed file中选定适合的数据,而不是去读guest 内存。下图给了大致示意图
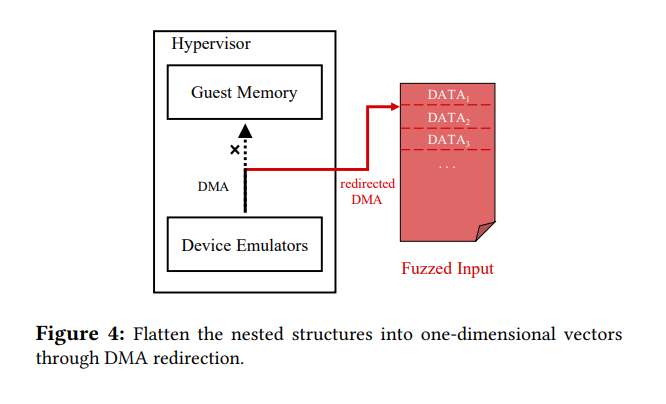
相比于传统的在guest中构建数据结构,V-shuttle从hypervisor中构建测试数据,从而把所有的多维数据结构变成了一维,并且保证了nested structure的语义。这样所有的底层代码都可以访问。对于每一次的模糊迭代,模糊器引擎首先通过突变的方式生成DMA数据序列,然后设备开始遍历树,然后每个DMA请求都从file中获取input。消除了每个节点中的指针,同时仍然保持每个节点隐含的指针依赖信息,所以这不会破坏设备的正常进行。
3.4 Semantics-Aware Fuzzing via SeedPools
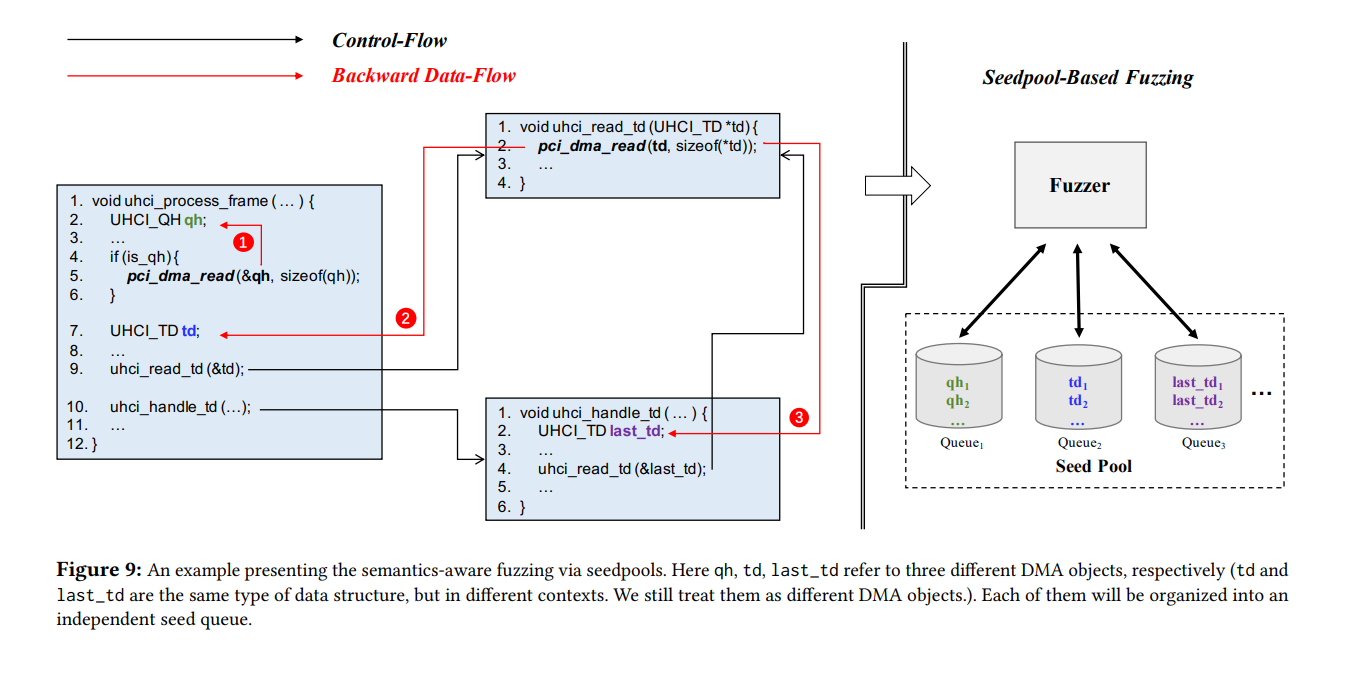
但是上面的方法也存在一个问题,就是它并没有把node type给考虑进去,所以效率会比较低。而且有些node type是动态决定的,所以有些时候控制流也是动态改变的。并且一些节点之间连接的语义也很容易在迭代的时候消失。(有个例子没看懂),然后就给每个fuzz数据加了一个type_id,这样同一类的node就可以更好的异变迭代。如下图,把接口中加了一个参数。

由此,就能够把数据结构之间进行解耦合,然后每个结构的数量又是有限的,所以独立地进行generate。
1)对DMA对象进行静态分析。大概就是backward data flow analysis(他们call这个叫live-variable analysis),通过一些函数(比如pic_dma_read),去反向找这些数据的type。(这块属实不是我的长项,就贴原文把
Therefore, we define a DMA object as a host’s structure that holds the copy of the guest’s data through DMA. Each DMA object represents a unique type of node. Aiming to label all the DMA objects, V-Shuttle performs static analysis on the hypervisor’s source code. In particular, V-Shuttle utilizes a live-variable analysis, which is a special type of data flow analysis. Considering the host’s buffer field of DMA operations (e.g., pci_dma_read, and its wrapped function) as the source, we do the backward data flow analysis from the source to its declaration or definition (the DMA object). After collecting all the DMA objects, we assign unique IDs to each of them. These labeled objects help us identify the node type of each DMA request at runtime and ensure that each type of DMA object can be correctly grouped)
2)通过每次读取input增加的type_id进行特定的读取。
3)同时为了解决多种类型的input,就扩展了AFL,增加了seedpool,这样就fuzzer在每个seed queue上变异,由此对每个type的structure单独变异出input。然后根据coverage的feedback反馈,就fuzzing就可以知道如何给每一种类型的type变异生成input。
4)语义感知 fuzzing过程。伪算法如下:

这里给了一个example:USB-UHCI:
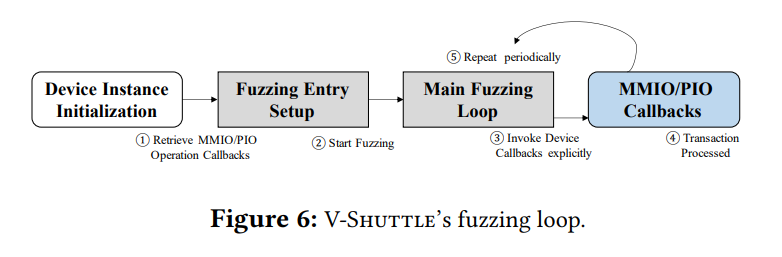
3.5 lightweight fuzzing loop
过去的方式通过在guest os中增加代理来实现,这样在vmexit的时候会造成很大的开销,但是此方法不会
环境主要功能模型:
5 evaluation
测试了Qemu5.1.0和VirtualBox6.1.14,